In the field of software engineering, the emergence of large language models (LLMs) designed specifically for code-related tasks has including AlphaCode (Li et al., 2022), SantaCoder (Allal et al., 2023), InCoder (Fried et al., 2022), CodeT5 (Wang et al., 2021), and DeepSeekCoder (Guo et al., 2024a) and Qwen-Coder (Hui et al., 2024), have been pre-trained on extensive datasets comprising billions of code-related data. Notably, models such as Starcoder (Li et al., 2023; Lozhkov et al., 2024), CodeLlama (Rozière et al.,
2023), DeepSeek-Coder (Guo et al., 2024a), and Code-Qwen (Bai et al., 2023) have advanced the capabilities of these systems. The advent of Code LLMs has revolutionized the automation of software development tasks, providing contextually relevant code suggestions and facilitating the translation from natural language to code. This discussion delves into existing literature and major contributions within the realm of Code LLMs, underscoring the progress made, diverse applications, and potential future developments in the field.
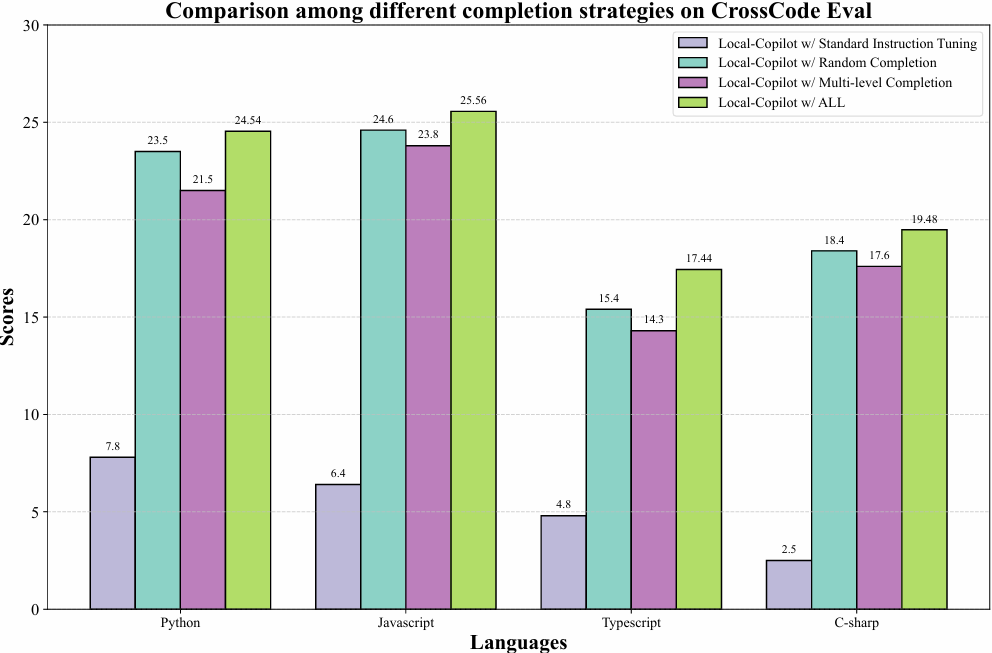
The code completion task holds paramount importance in modern software development, acting as a cornerstone for enhancing coding efficiency and accuracy. By analyzing the context of the ongoing work and using sophisticated algorithms to predict and suggest the next segments of code, code completion tools drastically reduce the time and effort programmers spend on writing boilerplate code, navigating large codebases, or recalling complex APIs and frameworks, which both accelerates the software development cycle and significantly diminishes the likelihood of syntax errors and bugs, leading to cleaner, more maintainable code. The recent code LLMs (Bavarian et al., 2022; Zheng et al., 2023) complete the middle code based on the prefix and suffix code through prefix-suffix-middle (PSM) and suffix-prefix-middle (SPM) pre-training paradigm. To correctly evaluate the code completion capability, the HumanEval benchmark (Allal et al., 2023; Zheng et al., 2023) is extended to the infilling task by randomly masking some code spans and lines and prompting LLms to predict the middle code. The recent works (Ding et al., 2023) propose to use the cross-file context to complete the current file and then score the results with n-gram string match. However, the community still lacks an executable evaluation repository-level benchmark from live repositories and the corresponding instruction corpora.
In this work, we benchmark, elicit, and enhance code repository-level completion tasks of open-source large language models (LLMs) by creating the repository-level instruction corpora
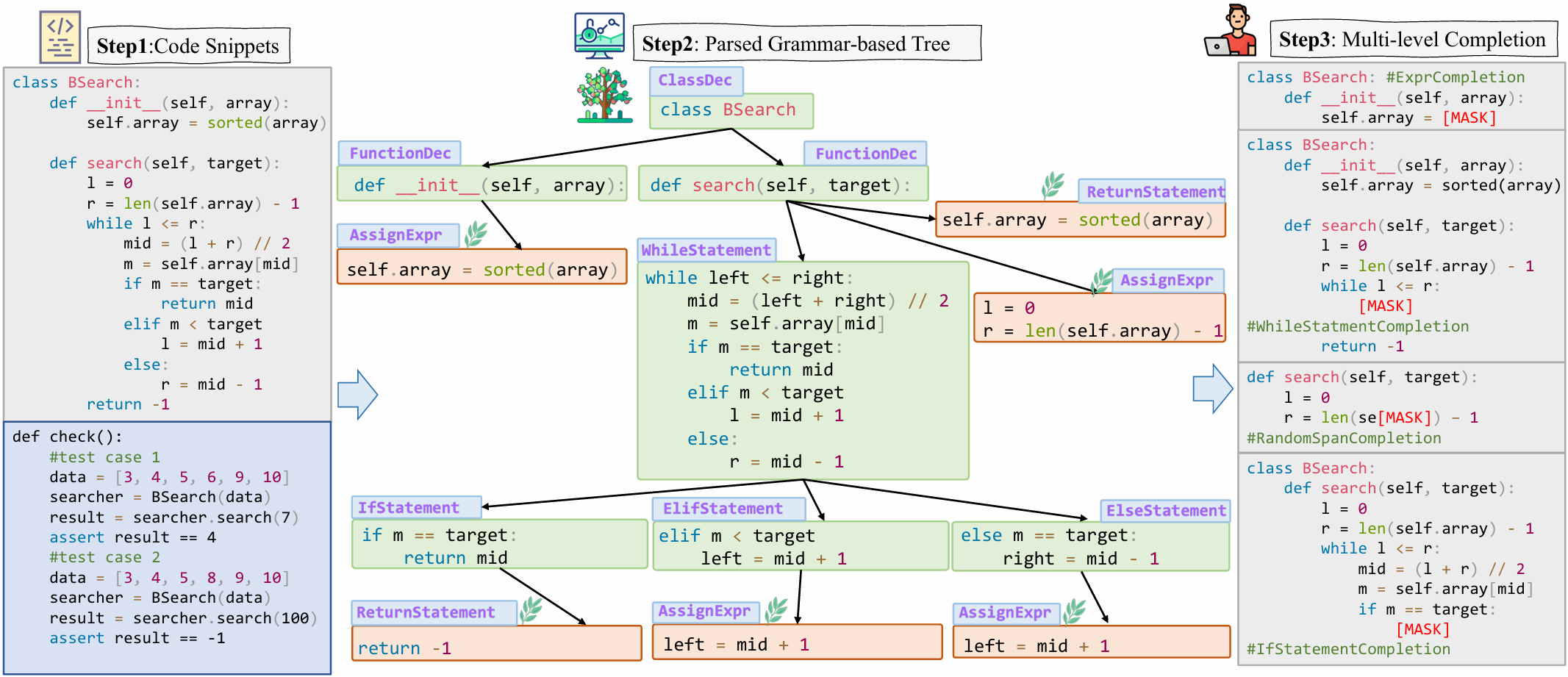
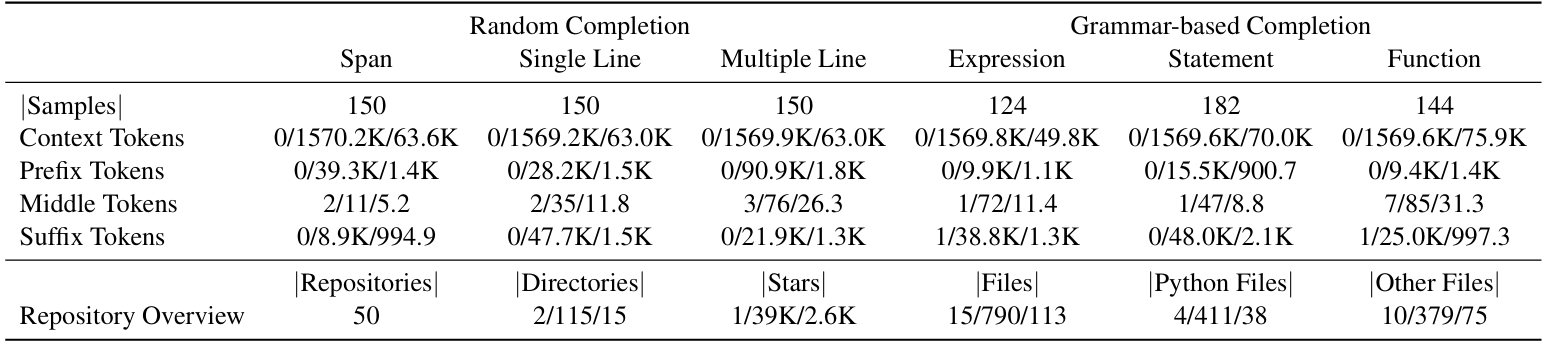
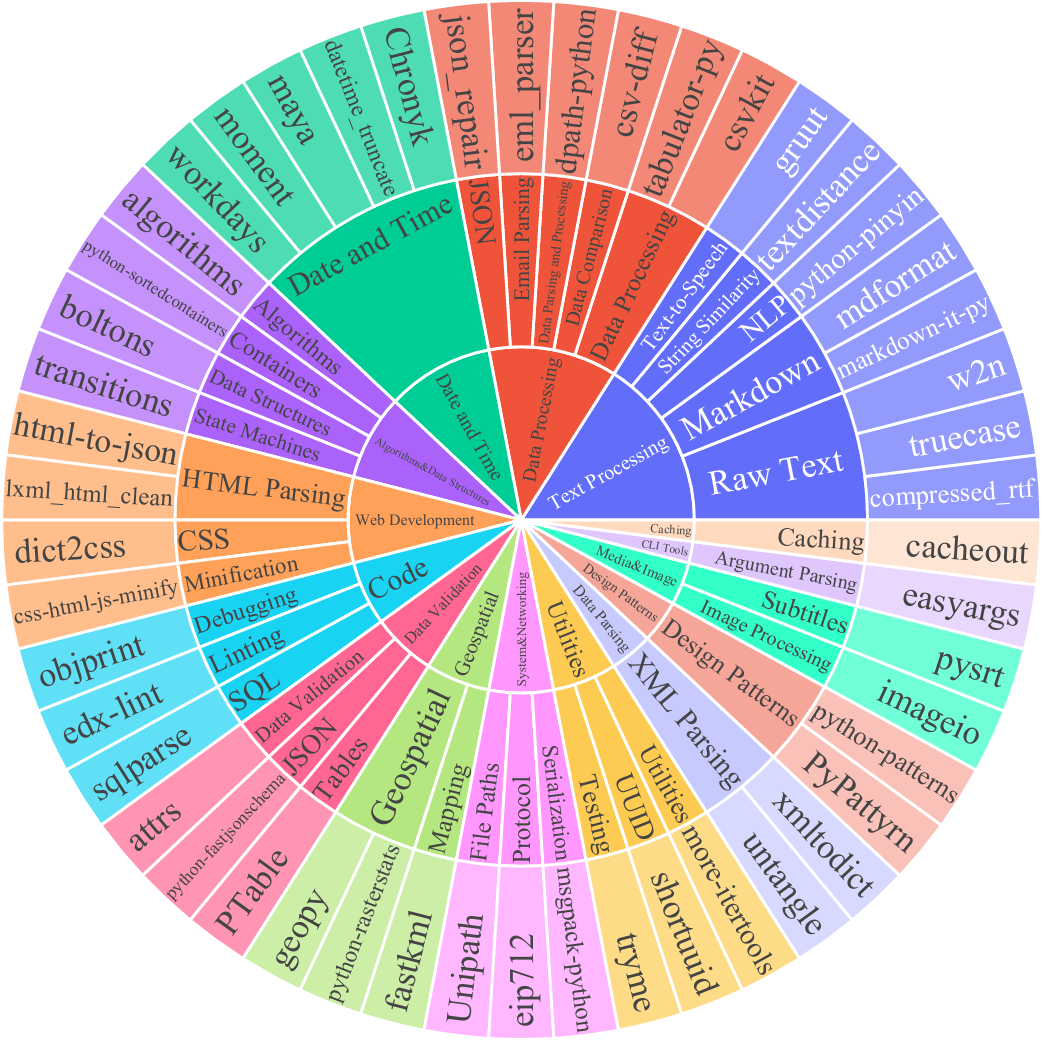
REPO-INSTRUCT and the corresponding benchmark EXECREPOBENCH for utilization and evaluation for code completion in real-world software development scenarios, where projects frequently involve complex dependencies across multiple files. Unlike previous benchmarks with text-matching metrics (e.g. exact match (EM) and edit similarity (ES)), we EXECREPOBENCH is constructed with repository-level unit tests to verify the correctness of the completion code, which contains 1.5K samples from 25 active Python repositories. To facilitate the attention of the community for the code completion task, we propose the multilevel grammar-based completion to create REPOINSTRUCT, where the code fragments under the different levels of logical units are masked for completion using the parsed abstract syntax tree (AST). During supervised finetuning (SFT), the code snippet of the repository is packed into the instruction data for the code completion LLMs Qwen2.5Coder-Instruct-C, where the query gives the prefix code of the current file, suffix code of the current file, and code snippets of other files.
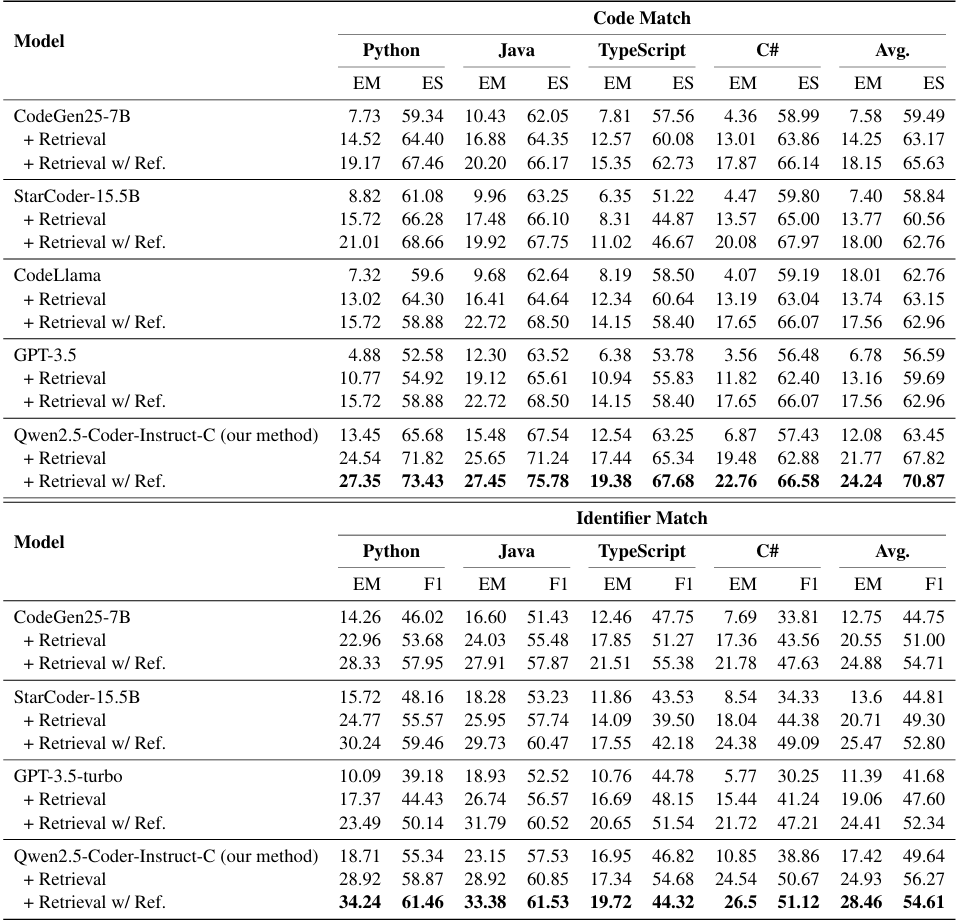
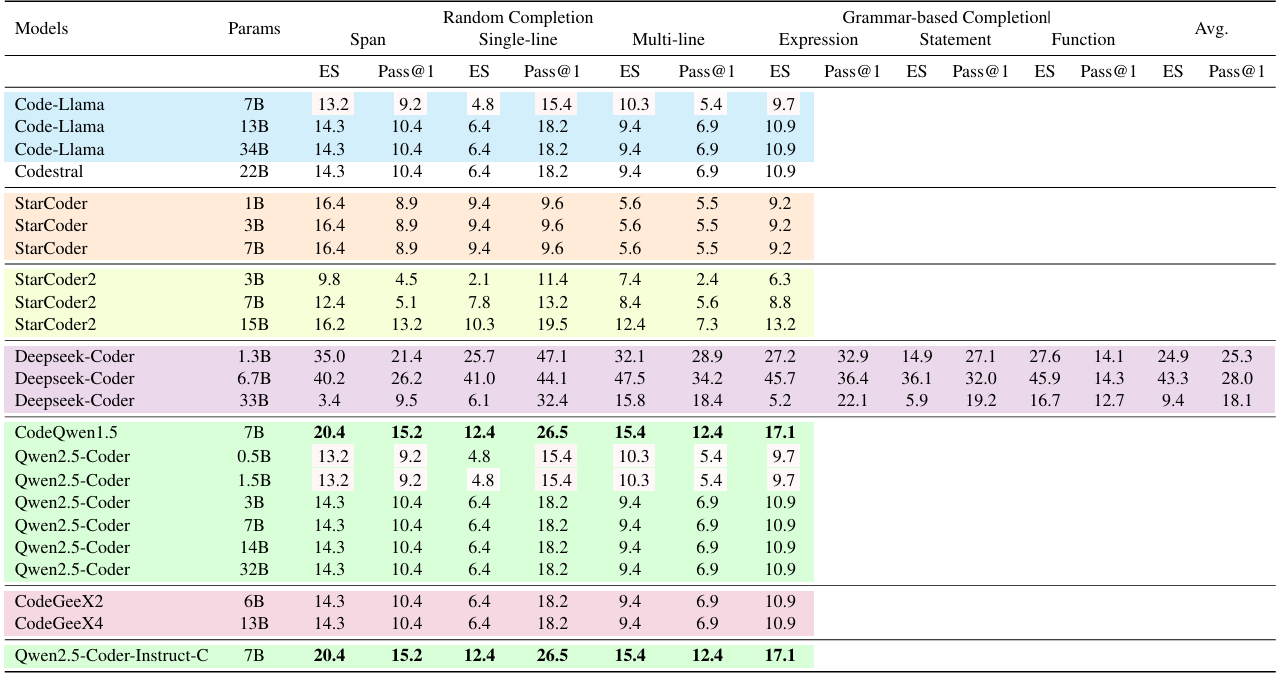
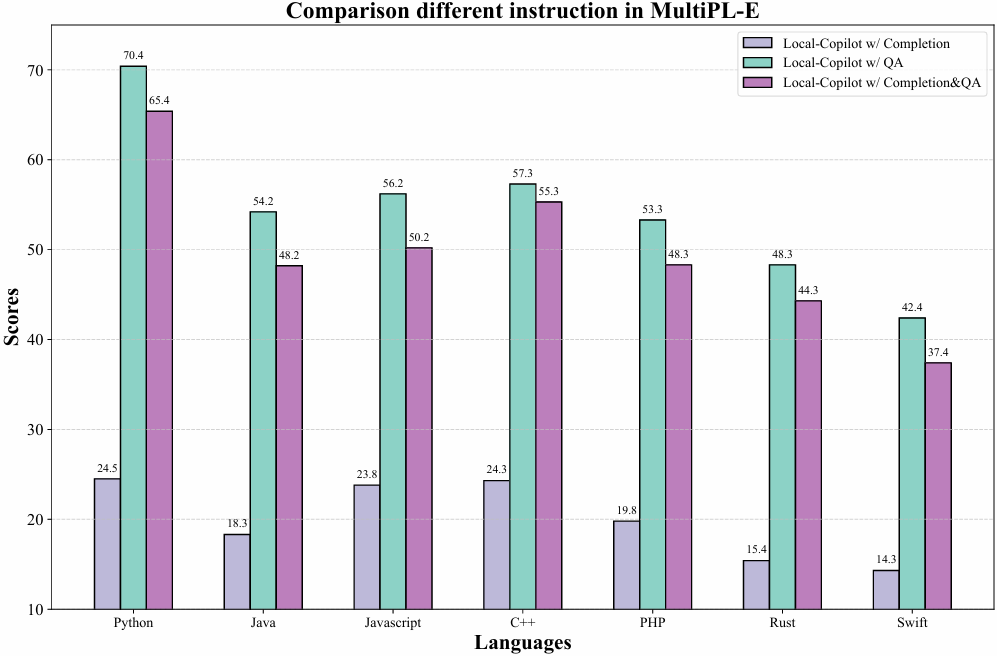
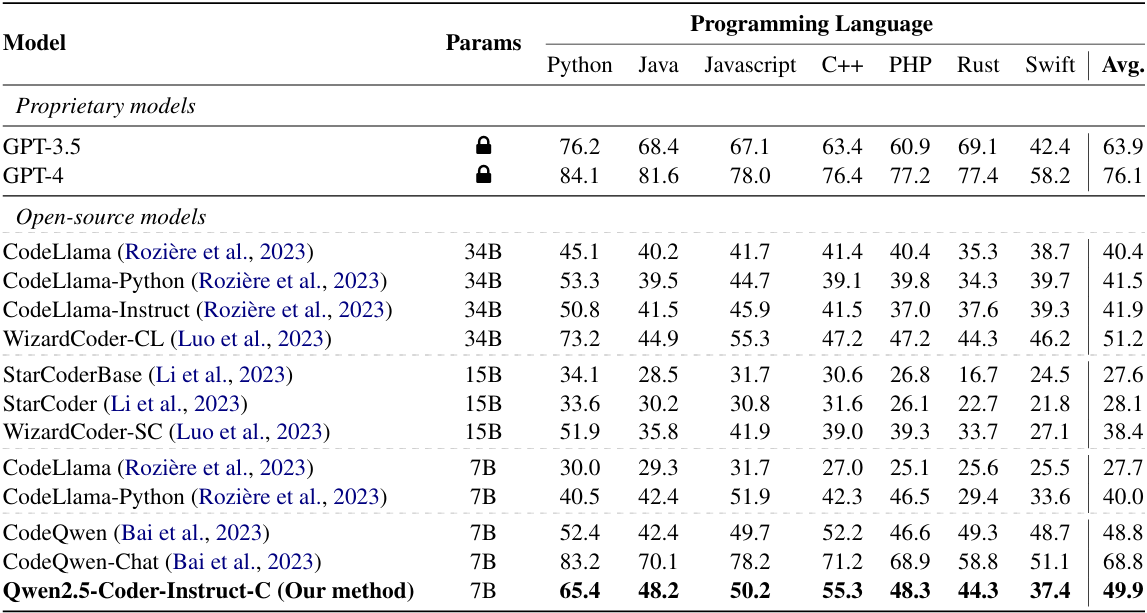
Qwen2.5-Coder-Instruct-C is evaluated on the CrossCodeEval (Ding et al., 2023) and our created benchmark EXECREPOBENCH. The results demonstrate that Qwen2.5-Coder-Instruct-C consistently achieves state-of-the-art performance across all languages, notably surpassing the previous baselines. The contributions are summarized as follows:
• We introduce executable repository-level benchmark EXECREPOBENCH for code completion evaluation, which collects the active repositories from GitHub and modify them into executable formats with test cases.
• We propose the multi-level grammar-based completion conditioned on the abstract syntax tree, where the statement-level,expressionlevel, function-level, and class-level code snippets are extracted for multi-level completion instruction corpora REPO-INSTRUCT
• Based on the open-source LLMs and the instruction corpora REPO-INSTRUCT, we finetune base LLMs with 7B parameters Qwen2.5Coder-Instruct-C with a mixture of code completion data and standard instruction corpora, which can be used as a local service for programming developer.